The challenges of scaling edge AI solutions
Moving your edge AI solution out into the field rapidly, and managing the solution remotely, is undeniably a challenge. However, help is on the way.
It’s been a while since I have written a longer Medium article; I was busy growing Scailable. About two years in, it’s a good time to reflect on the technology we built, or, more importantly, on why we built it. I hope this is meaningful for anyone venturing into the hot and quickly emerging world of “edge AI”.
With Scailable, we set out to enable managed deployment of edge AI solutions. Although there are many challenges associated with building an edge AI solution — both hardware and software — we focus on building a software platform to make the lives of those developing edge AI solutions at scale as easy as possible.
In this article, I will first very briefly detail what we mean by the term “edge AI solution”, and I will subsequently highlight the most important challenges anyone faces when building, deploying, iterating, and scaling such a solution. Finally I will detail how we try to solve these challenges.
So, the general setup of this article is simple:
- What is an “edge AI solution”: A simple overview of the common components present in any edge AI solution. Whether the solution is a “smart” camera recognizing license plates of cars, or an anomaly detection model running on a PLC based on vibration sensor data, abstractly it’s all the same. I will discuss the components without worrying too much about the specific application.
- Why is deploying and maintaining an edge AI solution hard? Interestingly, most people building their first solution grossly underestimate the challenges faced when scaling up. Moving from your laptop to the field is surprisingly tricky. I will simply list the most common challenges that we have encountered ourselves while creating dozens of successful solutions.
- Software tools to the rescue. In this final section, I will explain the edge AI middleware — and associated remote management platform — that we built with Scailable (and why we build it). I will try to highlight, where possible, alternatives and work-arounds as well: this article is not intended to promote what we built, just to explain why we built it the way we did.
A note of caution: In this article I will explicitly not address how to come up with or market commercially meaningful edge AI solutions. Commercially appealing solutions are omnipresent, and it is very clear that in virtually any industry running advanced ML/AI models on the edge can be economically viable. This ranges from the early detection of production anomalies in industry (where the business case of early discovery is often easy to make), to reducing false alarms in mobile security masts (saving costs for every false positive), to inspecting the debarking process of trees in paper making to improve the product quality (here). I will also not bother discussing why — in many applications — moving the AI model (i.e., the actual processing) to the edge instead of the cloud is beneficial. The latency, costs, security, and privacy benefits are obvious.
What is an Edge AI solution?
To explain all the terms, let’s focus on a simple (but sufficiently rich) practical example:
Imagine a production company creating drawer slides (here is an example). The company wants to use a camera and some AI/ML model to inspect the quality of the slides after bending the metal. When a bend is not proper, the machine should be temporarily halted and the operator should be notified.
This is a very simple edge AI example with immediate business value: the early detection of deficiencies prevents a costly accumulation of errors (the current standard of the company is to take samples and inspect these manually, leading to the risk that quite a large batch of products has to be discarded). There is way more to the actual case, but this is sufficient to explain all the bits that go into making the solution. Let’s focus on a few simple questions first to sharpen definitions, and next look at the components in the solution that are common to virtually all edge AI solutions.
Where is the “AI model” in this story?
From a functional point of view, we simply aim to create an algorithm that turns an RTSP stream (as generated by the camera inspecting the products) into a boolean indicating whether the product is OK or NG (Not Good :)) and subsequently both stops the machine and notifies the operator. In our jargon the “AI model” here is the part of this algorithm which receives a numeral tensor as input (a nCHW tensor encoding at least one image) and produces a boolean (true / false) as output.
In some ways, there is no clear boundary between the “AI model” and the surrounding pipeline (see below): both join forces to create the fully functional algorithm. However, we often think about the AI model as the part of the algorithm that was not hard-coded by an engineer, but rather was created by having a computer learn from examples. Again, this is not strict: if you think about the AI model as a computational graph (which we do very explicitly as we often work with ONNX), adding post-processing to turn bounding boxes of objects (as resulting from a standard YOLO-type architecture) into a count of the number of objects) can be done inside the “AI model”. That said, in many applications the “AI model” part is iterated multiple times to achieve a certain performance (in terms of accuracy), while the surrounding bits of the full algorithm remain relatively static: it is thus useful to separate the AI model from the surrounding software.
Technically, at some point, the “AI model” is just a modular part of the full algorithm that often is created using modern model training tools (e.g., edge impulse, tensorflow, PyTorch, etc.). However, it could just as well have been created from scratch: see “Creating an ONNX graph for image processing from scratch”.
What is an edge device?
We often get this question which makes sense since we enable edge AI. With an edge device we simply mean any piece of hardware that is not located in some central cloud (i.e., not in a server rack somewhere in a large data center) that has sufficient computing power to do meaningful things. Depending on the AI model and the surrounding application, this might be a small MCU, to a gateway with a simple single core ARM chip (we do use these a lot for edge AI), to much larger edge computers that contain dedicated AI hardware (such as NVIDIA GPUs).
Common Edge AI solution components: the pipeline
Putting it together, it is nice to conceptually think about the full algorithm for recognizing production deficits as a pipeline that schematically looks as follows:
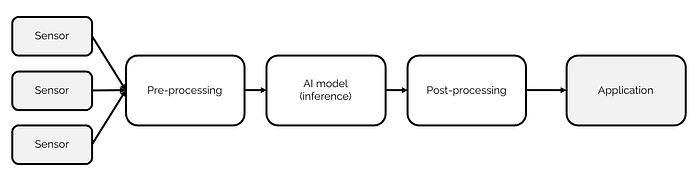
The common components here are easy to define:
- Input sensors: The whole thing starts with the input sensor, in this case a camera. The camera might produce individual images, or an image stream (in one of various formats). In our setup we used a “dumb” camera that generates an RTSP stream which is subsequently sent to an edge device (we used the Advantech MIC730) for this specific case).
- Input pre-processing. The next conceptual part of the pipeline is the input pre-processing: here we decode the stream, turn the images into numeric tensors, normalize the images, and “feed” them to the model.
- The AI Model. As explained above, in this case the model turned a tensor into a boolean. The model in this case was actually created using a number of custom “vision” tricks (implemented in ONNX), and a YOLO architecture retrained to identify specific parts of the slide.
- Model output post-processing. The boolean output needed to be routed in various ways to ensure the business value. An MQTT connection with the machine was set up to stop the machine when the output was false. Next, via REST, the actual input image that generated the error was sent to a higher level application.
- Application layer. In this case we used Node-RED for visualization and providing feedback to the operator. However, we have used many application layers; for example Nx is a great platform when the main input to the pipeline is visual.
Effectively, all of the components above, both hardware and software, need to come together to create value. The same components are in every edge AI solution: whether it is monitoring highway traffic, detecting vibration anomalies in engines, or monitoring construction worker safety, we always need input sensors, pre-processing, an AI model, post-processing, and a higher level application platform.
Now, let’s turn to why moving from an AI model that seems to work well on your laptop (or in the cloud) on individual training images to the actual functioning edge AI application running on thousands of sites is challenging.
Why is deploying and maintaining and edge AI solution hard?
Ok, so I am assuming you have a great application in mind, and a great solution. You have also trained your AI model (tensor in, tensor out) and it is running flawlessly on your laptop (or in the cloud). Now, you want to run the model in real-live, on a real edge device, at scale. Here is what you will have to worry about:
1. Selecting your target device
First up, and very much outside of the comfort zone of many AI / ML developers, is the selection of the right target device. What chipset do we need? What camera? What are the temperature and moisture conditions? What ports do we need? What is the hardware availability? etc. etc.
Selecting the right hardware is tricky, especially if you are a data scientist with a more software oriented background.
2. Rebuilding your model for your target device
Once you have selected your target device — and at this point you just hope your pipeline will run on the target since you haven’t tried it yet — you are often faced with significant engineering challenges, starting with the model itself: Does your device have an NXP NPU? or a HAILO accelerator? or an NVIDIA GPU? Orin? Nx? Is the CPU ARM based? Intel?
It often takes significant effort to “port” your model, trained using whatever training tools you felt comfortable with, to a format that actually reaps the benefits of the underlying hardware. You might need to use compilation toolchains provided by the accelerator manufacturer, only to find out that parts of your model architecture are not supported. You might need to re-assess the performance of your model as the model is automagically pruned and parameters are quantized (neither of these being fully lossless). It can take days or even weeks to ensure that your trained model can be run efficiently on the target hardware (even when using some of the industry standard tools).
3. (Re)building your pipeline for your target device
But just porting your model doesn’t complete your pipeline. How do you grab the images from the camera and resize them efficiently? And what if you have multiple cameras or a host of other sensors? Yeah, of course, stick in a container and write some python glue: on smaller edge devices this will simply be impossible, but even on larger edge devices you will suffer in highly needed performance (which is quite annoying after just having optimized your model painstakingly for the target hardware).
Building low-level, highly performance, pre-and post-processing blocks takes significant embedded engineering skills (but interestingly, between edge AI applications, there are loads of commonalities; so, why are you spending so much engineering time to reinvent the wheel?)
4. Actual deployment, i.e., installing and distributing your solution
Once you have your model tailored to your device, and once you have a low level, highly efficient implementation of your pipeline — which again might be device specific — you now want to actually get all of this software running on the actual device…
…To many this does not seem problematic at all; ship the device to your desk, get it online or otherwise get access to it, and simply copy or flash, or otherwise move the software to the device. It only takes a few hours!
Well, and next the business wants to scale up to thousands of devices. And in the meantime the camera specs change (slightly different input resolution this time), and you have iterated your model. Is that going to mean a few hours per device for every update? Even if these devices end up being located in factories (or other sites) around the world? What seemed to be easy enough is going to be a large challenge when it’s at scale, needs to be secure, and is geographically spread out.
5. Integrating in a larger software eco-system.
You are getting closer and closer to the actual solution. Your AI model is running on the edge device, the pipeline is running and configured, and you are generating inferences. In the easiest case — just thinking about a vision-based edge AI solution — you might be generating bounding boxes, that’s x,y,h,w- coordinates and a class label. Sure, we recognized the position of the drawer slide; what’s next?
Edge AI solutions are never done at the inference stage. The business benefits only if the solution is integrated into the appropriate application frameworks. For security or logistics applications this might mean integrating the inferences into a powerful VMS system like Nx. Or, for industrial applications, this might mean routing the inferences to directly interact with cobots or operators, using an application platform like Node-RED. Integrating anew, for each project or solution, is a pain.
6. Iterating your solution to improve
Let’s assume you also managed to integrate the edge AI solution into the larger application eco-system such that the business value is guaranteed. Well, you will find that your model is — quite rapidly and most likely — not the “best” model out there. We see that even ostensibly simple security models that recognize people and vehicles are updated and improved continuously. Let alone models that are used in ever-varying production environments. The drawer slides are made according to the specifications of the end-customers; your models (or pipeline, depending or where you want to put the boundaries) will need to change often.
So, you need a mechanism to improve. Potentially you will need to collect new training instances. You will need to be able to test your newly trained models, and deploy them securely to thousands of devices. Each iteration effectively presents the same challenges all over again.
Pff.. that sounds like quite a few challenges. Luckily, there is hope.
Yes, yes, yes, these are definitely not all the challenges. For one, understanding performance of your pipeline in terms of both accuracy and computational speed on the target hardware and in the field is a challenge on its own. However, this article is already way too long so I am skipping some bits.
Middleware. Sexy it is not, but it works like a charm.
In this last section I will describe how we at Scailable ended up addressing most of the challenges listed above. And yes, you can benefit from the solution we build and I will add a link down below just in case you want to learn more. I hope though that this article is interesting more generally as we outline the way we made this work.
Let me just take it challenge by challenge.
Admittedly this part of the article is somewhat promotional. Hard to get around: we spent two years building this thing and we like what we build. However, I am trying to focus on general principles.
1. Selecting your target device
A, this one we actually don’t really solve; we are a software company. That said, we partner with hardware companies that pre-install our middleware (more on this below), which makes the devices we support appealing as a deployment target. However, given weather requirements, heat, processing speed, I/O, etc., there is still a whole list of potential devices to choose from.
Our supported devices list is growing weekly. If you want to have your device supported, please let us know.
2. Rebuilding your model for your target device
The “model rebuilding” has been our focus from the get-go with Scailable. We saw a tsunami of chipsets and architectures coming our way, and we noticed that too often software (i.e., the AI model specification) and hardware (chipset, accelerators) are highly dependent. This makes that you either suffer in your choices of modeling tools, or you become tied in to a specific hardware vendor. A dependency you don’t want.
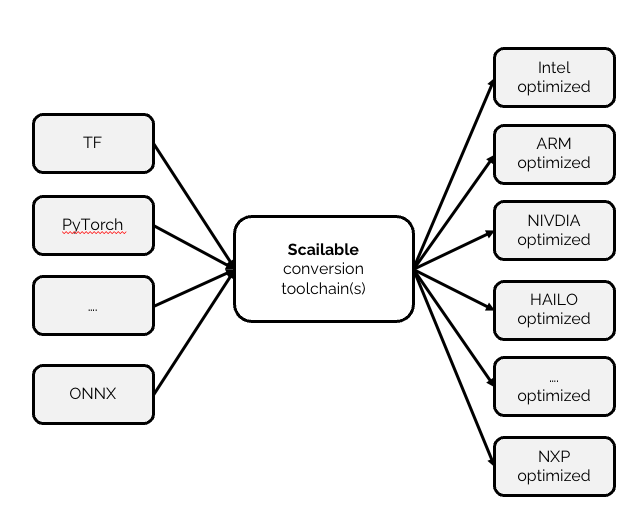
We solved this issue by effectively building toolchain(s) that automatically consume a model specification in any standard format, and convert them to optimized versions for all the devices that we support. Given our huge experience, we can easily add accelerators and chipsets, and ensure a model (given its size, its operations, etc. etc.) is fully optimized for the target. We use core-C, Web-assembly, ONNX, etc. as our targets, depending on the target device. Interestingly, this means that a user only has to focus on the functionality of the model; once uploaded to Scailable, our toolchains will make the exact same model — conversion is by default one-to-one — available for a variety of targets. So, that’s days (or weeks really) of re-engineering a model, fully automated.
3. (Re)building your pipeline for your target device
Of course, you can build your pipeline in a docker container using python glue; that’s what you would do if you started training your models using python tooling. However, what if your target device has severe resource limitations? Or what if you just want absolute performance? Or what if you simply don’t want to reinvent the wheel?
With Scailable, we effectively build the full pipeline in modular blocks, fully in c. Our pipelines are extremely performant and have an extremely small footprint. They are fully modular and thus it is easy to change sensors, pre-processing rules and/or post processing rules, without intervening with the AI model. Additionally, for supported devices, we will use the hardware as efficiently as possible for any standard pre- and post-processing tasks.
We provide an SDK for all the bits of the pipeline. And, for most common pipeline tasks, such as virtually any vision task, you don’t need to build anything: the pipelines are there for you to use. You simply configure your input sensors, your model, the pre- and post-processing rules, and you are good to go, no-code.
4. Actual deployment, i.e., installing and distributing your solution
The challenge that most only understand when it's too late…. How to deploy and manage a large fleet of devices running an edge AI solution?
We basically build a full management platform for our pipelines. The full pre-processing and post-processing settings (and even custom added blocks) can be managed easily and remotely. Simply purchase a device with our middleware (that’s our pipeline) pre-installed, and you can remotely configure all the bits and even swap models.
We set it up in such a way that the pipeline itself, and all the pre- and post-processing options, are governed through a simple settings file that can easily be extended and configured both locally and remotely. The pipeline, after configuration, can run without an internet connection. Within the pipeline, the model itself can be swapped, and all of this can be done for a large fleet of devices, flexibly grouped, all at once. This is where you save valuable time while scaling up!
5. Integrating in a larger software eco-system.
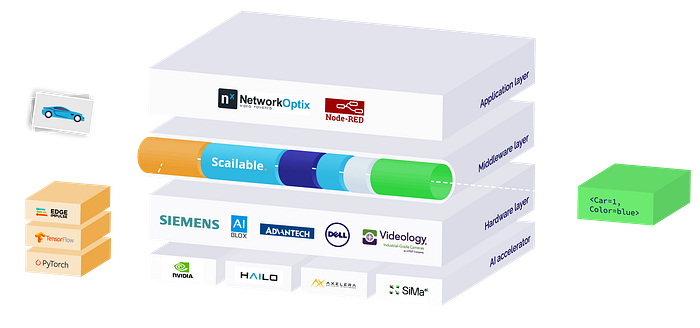
So, using the tools we developed you are now at a point that you are basically hardware agnostic, can move your model and pipeline to a device remotely, and simply configure all your pre-and post processing. To truly unlock the business value however we need to integrate with application platform(s). And thus we do. Our pipelines are easily configured to work with Network Optix, Node-Red, and a variety of other applications.
6. Iterating your solution to improve
I guess by now this last challenge is a no-brainer: simply configure the pipeline — by setting some post-processing options — to sample for new training instances. Next, use any training platform, such as Edge Impulse, to label and re-train your model. And once you are done, simply deploy your updated model to all of your devices at once, instantly.
Pretty cool.
Wrap up
Developing edge AI solutions is a challenge, period. You have to tie together great business sense, AI skills, hardware knowledge, and embedded engineering skills. And, as the field is moving rapidly, you have to keep up with new hardware, new software tools, new model architectures, new training platforms, etc. etc. Not easy.
With Scailable, we are trying to make some parts of the process easier (you can’t do it all): focusing on managed deployment for supported devices, we aim to make your model development independent of your hardware (obviously within limits of the computational capabilities of the target hardware) and accelerate both go-to-market and future iterations.
With what we built — a combination of model conversion toolchains, cloud management tools, and on-device pipelines — we have reduced the time it takes to build an edge AI solutions start-to-end from months to at most days, sometimes minutes. We have abstracted away the complexity, or most importantly, the dependence between the hardware target and the model functionality.
That’s it. Interested in learning more? Contact Scailable, book a demo, or see the Scailable docs. Thanks.
